How to Secure Vercel Cron Job routes in Next.js 14 (app router)
Learn how to manage Cron Jobs effectively in Vercel. How to stay in the Hobby plan while executing multiple API requests. Learn how to manage Cron Jobs effectively in Vercel. Explore cron job duration, error handling, deployments, concurrency cont...

I’m the founder of CodingCatDev, where we create “Purrfect Web Tutorials” to teach the world how to turn their development dreams into reality. I am a professional full stack developer, and I am passionate about mentoring new developers and helping the community that has allowed me to live my development dreams. I firmly believe that anyone can learn to be a developer. The CodingCatDev team is here to help!
Original: https://codingcat.dev/post/how-to-secure-vercel-cron-job-routes-in-next-js-14-app-router
Use Case
Protect your cron job routes to ensure they can't be accessed by anyone with the URL. We need to guarantee that only Vercel's servers can trigger these jobs. To achieve this, we'll use a CRON_SECRET in our environment variables. Vercel will automatically include this secret as a bearer token in the request headers, adding an extra layer of security. This way, you can rest easy knowing your cron jobs are safe from unauthorized access.
TLDR
The image below is the fastest setup possible for a cron job. In the additional details below I walk you through setting up a cron job and pulling YouTube statistics.
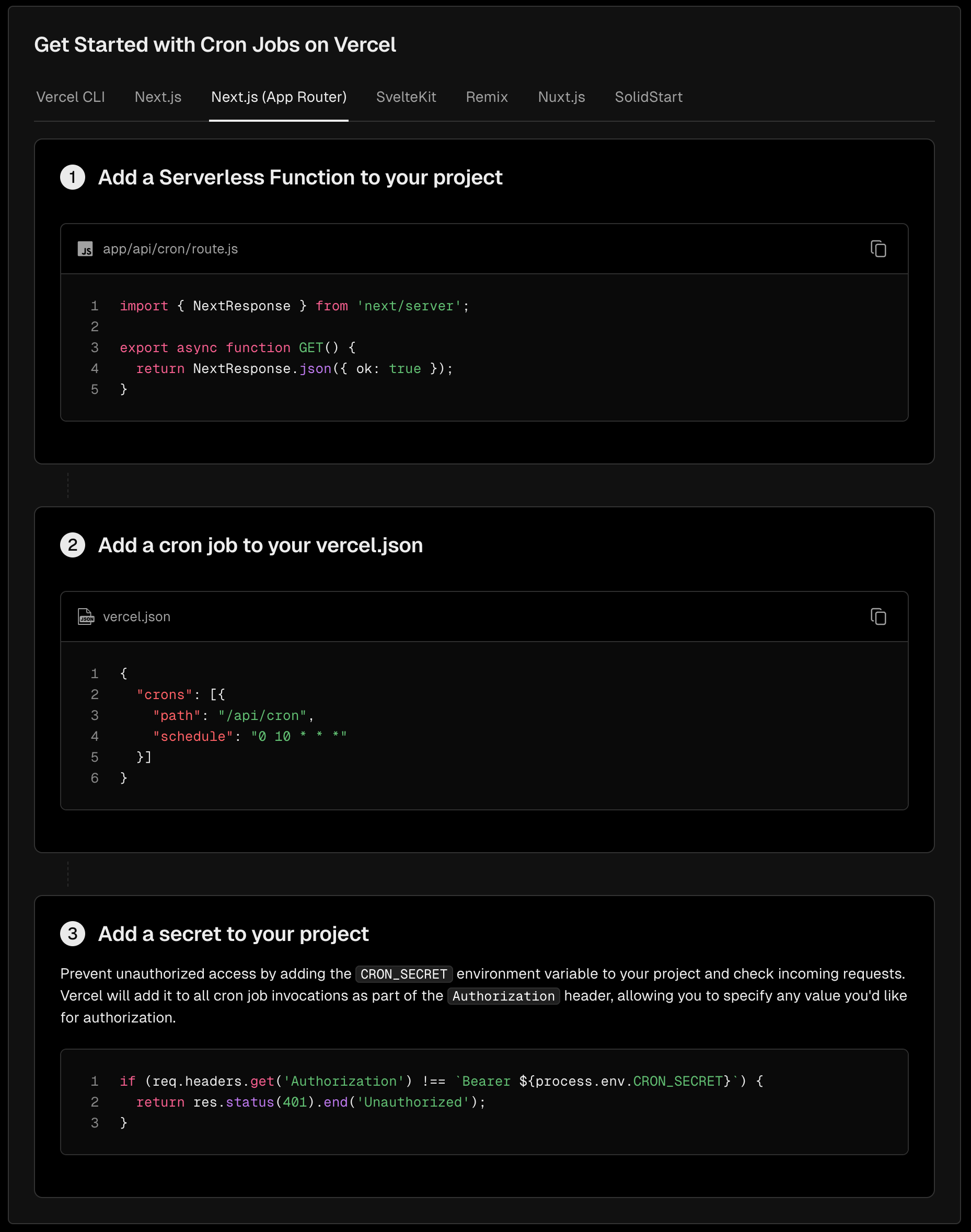
Basic Limits
There are a few key features to remember if you are running Next.js on the hobby plan of Vercel, duration, memory, and amount of cron jobs. I call attention to these two because setting up your cron job to do all the work will most likely lead to failure, in some minimal cases this might work for you, but ideally, you want something of a publish-subscribe method.
Max Duration
Max Duration the default for this is 10 seconds, while the maximum is 60 seconds.
This refers to the longest time a function can process an HTTP request before responding.
Functions using the Edge runtime do not have a maximum duration. They must begin sending a response within 25 seconds and can continue streaming a response beyond that time.
While Serverless Functions have a default duration, this duration can be extended using the maxDuration config. If a Serverless Function doesn't respond within the duration, a 504 error code (FUNCTION_INVOCATION_TIMEOUT) is returned.
Memory Limits
The limit on Vercel's Hobby plan is 1024 MB / 0.6 vCPU.
Cron Limit
The Hobby plan has a limit of 2 cron jobs, the Pro plan has a limit of 40. Remember this when architecting your cron solution. At the bottom of this post, I have examples of doing YouTube Data V3 API lookups for every video in CodingCat.dev's collection and reporting back that day's views.
Create Secure Endpoint
You can find more details about this in Vercel's Securing cron jobs.
Generate CRON_SECRET
Create a secret key using the below command or something like 1Password to generate a key that is at least 16 characters (in this example we use 32). This is just like a password so make sure not to check this into a git repository.
openssl rand -hex 32
Copy this key and save it locally in .env.local assigned to CRON_SECRET variable like below.
CRON_SECRET=39e2aca39a84bb22e86665e3ce6146007c61ce0ca3da1798891e202c885f538a
Route Handler
In the below example, you will create a GET handler that will check for the Bearer authorization header. Create this file in app/api/cron/route.tsx.
import type { NextRequest } from 'next/server';
export function GET(request: NextRequest) {
const authHeader = request.headers.get('authorization');
if (authHeader !== `Bearer ${process.env.CRON_SECRET}`) {
return new Response('Unauthorized', {
status: 401,
});
}
return Response.json({ success: true });
}
Now you can test this function locally to see if you get a success message back by running the below command.
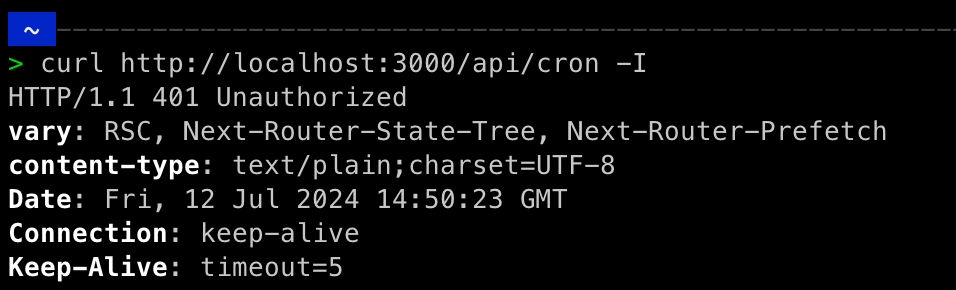
curl -I http://localhost:3000/api/cron
With this command, you should see that anyone trying to access your endpoint that runs the cron job will fail because they have not sent the correct authorization header like Vercel does when issuing the job. In the below screenshot, you will see where the endpoint returned a 401 Unauthorized.
Now issue the command passing the correct authorization header like below. Pay close attention to include Bearer before your CRON_SECRET.
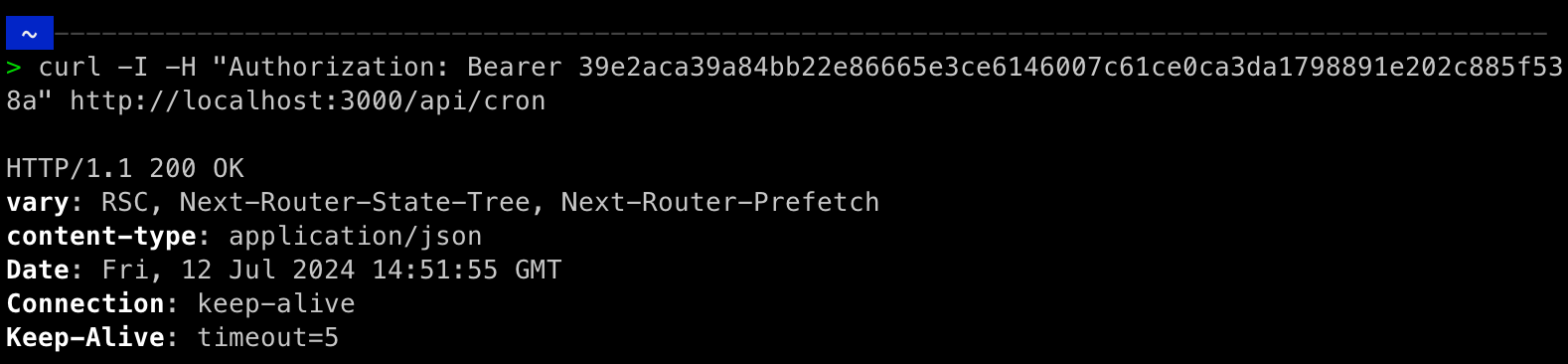
curl -I -H "Authorization: Bearer 39e2aca39a84bb22e86665e3ce6146007c61ce0ca3da1798891e202c885f538a" http://localhost:3000/api/cron
As you can see in the result below you will now get a HTTP status of 200 OK.
Production
Now that you have tested your cron endpoint locally it is time to get ready for production. Vercel cron jobs will only run on your production deployment. I wish this wasn't true because I like testing off of our dev branch but I guess you can't win them all 😉.
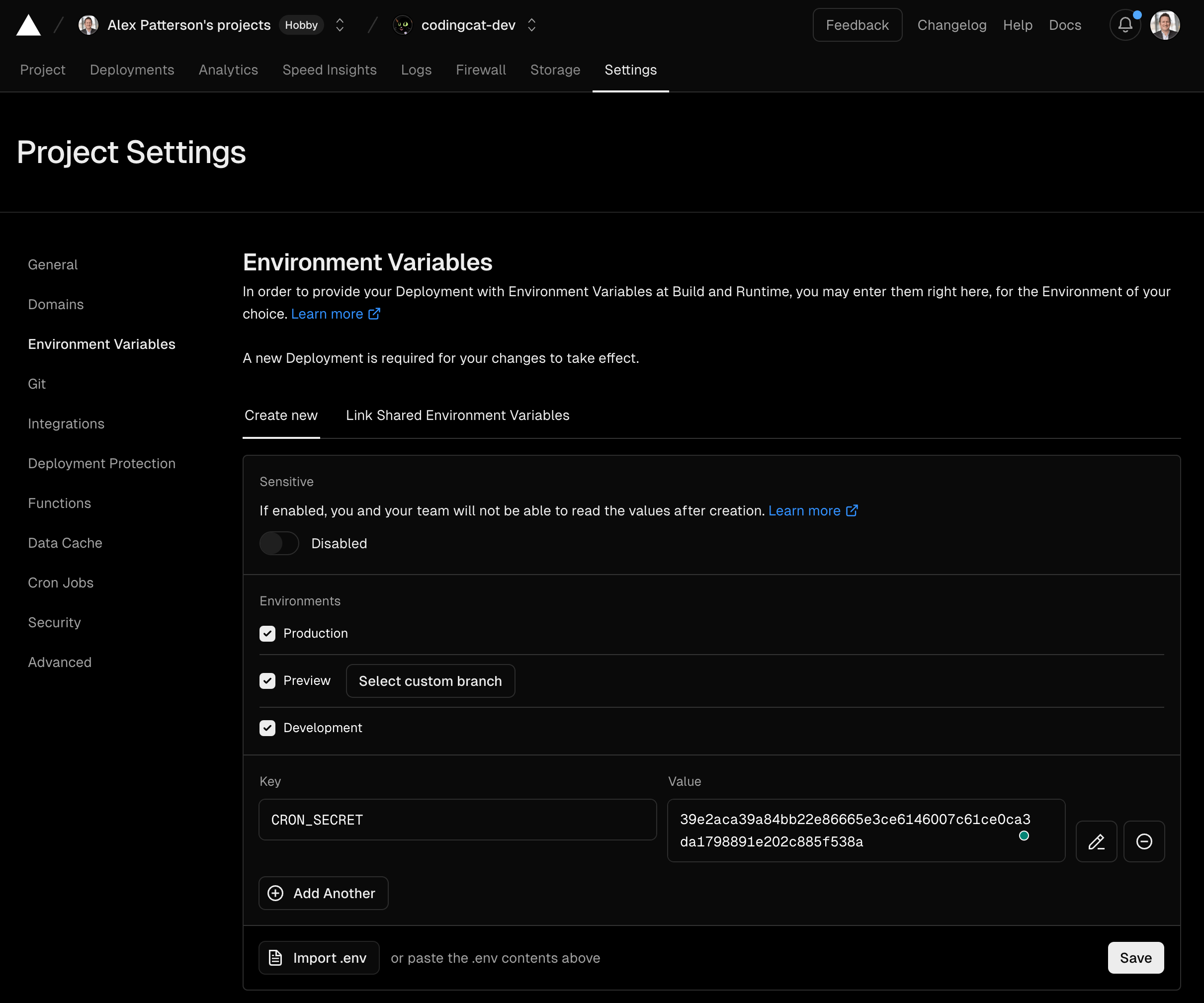
Vercel Environment Variables
You can copy and paste your environment variable directly into your project settings. You can either leave this checked for all deployments or only check production since these will only run in production. The below screenshot shows the current way of saving this environment variable.
Update Vercel Project File
To set up a cron job you need to have a file located at .vercel/project.json that will include the path to call for the cron job and the schedule. In the below example, I have set my cron job to trigger every day at 5 pm (or 17:00). Try crontab guru to get the settings exactly how you want them.
{
"projectId": "prj_123",
"orgId": "team_456",
"crons": [
{
"path": "/api/cron",
"schedule": "0 17 * * *"
}
]
}
Now you can push the change to your production branch so that the cron job will start running.
vercel deploy --prod
Next Steps
Now that you have a cron job setup you will need to typically create another dynamic endpoint that will allow you to call those services in a multithreaded fashion.
Below is the cron endpoint created just like above with one addition that it also triggers a new API call /api/youtube/views, passing the same CRON_SECRET so that the same route can be protected as well.
import { publicURL } from '@/lib/utils';
import type { NextRequest } from 'next/server';
export function GET(request: NextRequest) {
const authHeader = request.headers.get('authorization');
if (authHeader !== `Bearer ${process.env.CRON_SECRET}`) {
return new Response('Unauthorized', {
status: 401,
});
}
// Don't await just trigger
console.debug('youtube views triggered');
fetch(publicURL() + `/api/youtube/views`,
{ headers: { authorization: `Bearer ${process.env.CRON_SECRET}` } });
return Response.json({ success: true });
}
YouTube Statistics using Data API v3
CodingCat.dev has a Sanity.io backend so some updates are happening here that need some explanation, if you are not used to Sanity don't worry about it they are just like any other database that you might be using to store data.
Below is the full code and functions as a completely self-contained API. This means at any point I can manually trigger the API to update any YouTube statistics for a post that is associated. That means if my next podcast episode starts blowing up I can immediately get it on our front page as a top podcast, or trending podcast to watch. Then based on our cron schedule from above it will run every day at 5 pm so we never miss adding stats.
import { publicURL, youtubeParser } from '@/lib/utils';
import { createClient } from 'next-sanity';
import type { NextRequest } from 'next/server';
const sanityWriteClient = createClient({
projectId: process.env.NEXT_PUBLIC_SANITY_PROJECT_ID,
dataset: process.env.NEXT_PUBLIC_SANITY_DATASET,
token: process.env.SANITY_API_WRITE_TOKEN,
apiVersion: '2022-03-07',
perspective: 'raw'
});
export async function GET(request: NextRequest) {
const authHeader = request.headers.get('authorization');
if (authHeader !== `Bearer ${process.env.CRON_SECRET}`) {
return new Response('Unauthorized', {
status: 401,
});
}
const searchParams = request.nextUrl.searchParams;
const lastIdParam = searchParams.get('lastId');
try {
// Assume if lastId is missing that the request will be the initial starting the process.
const sanityRead = await sanityWriteClient.fetch(
`*[youtube != null && _id > $lastId]| order(_id)[0]{
_id,
youtube
}`, {
lastId: lastIdParam || ''
})
const lastId = sanityRead?._id;
if (!lastId) {
const message = `No doc found based on lastId ${lastId}`;
console.debug(message);
return Response.json({ success: true, message }, { status: 200 });
}
// These should never match, if they do bail.
if (!lastId && lastIdParam) {
console.error('lastId matches current doc, stopping calls.');
return new Response('lastId matches current doc, stopping calls.', { status: 200 });
}
const id = youtubeParser(sanityRead?.youtube);
if (!id) {
console.error('Missing YouTube Id');
return new Response('Missing YouTube Id', { status: 404 });
}
const videoResp = await fetch(`https://www.googleapis.com/youtube/v3/videos?id=${id}&key=${process.env.YOUTUBE_API_KEY}&fields=items(id,statistics)&part=statistics`)
const json = await videoResp.json();
if (videoResp.status !== 200) {
console.error(JSON.stringify(json));
return Response.json(json, { status: videoResp.status })
}
console.debug(JSON.stringify(json));
const statistics = json?.items?.at(0)?.statistics;
if (!statistics) {
const words = `No statistics found for YouTube Id ${id}`
console.error(words);
return new Response(words, { status: 404 });
}
// Update current doc with stats
const sanityUpdate = await sanityWriteClient.patch(lastId).set({
'statistics.youtube.commentCount': parseInt(statistics.commentCount),
'statistics.youtube.favoriteCount': parseInt(statistics.favoriteCount),
'statistics.youtube.likeCount': parseInt(statistics.likeCount),
'statistics.youtube.viewCount': parseInt(statistics.viewCount),
}).commit();
// Trigger next call, don't wait for response
fetch(publicURL() + `/api/youtube/views?lastId=${lastId}`,
{ headers: { authorization: `Bearer ${process.env.CRON_SECRET}` } });
return Response.json(sanityUpdate);
} catch (error) {
console.error(JSON.stringify(error));
return Response.json({ success: false }, { status: 404 });
}
}
I would highly recommend writing all of your cron jobs like this so that they initiate another process to avoid the limitations in place as described above. Each invocation of the YouTube Data API and update to our sanity backend takes about 1 second.




